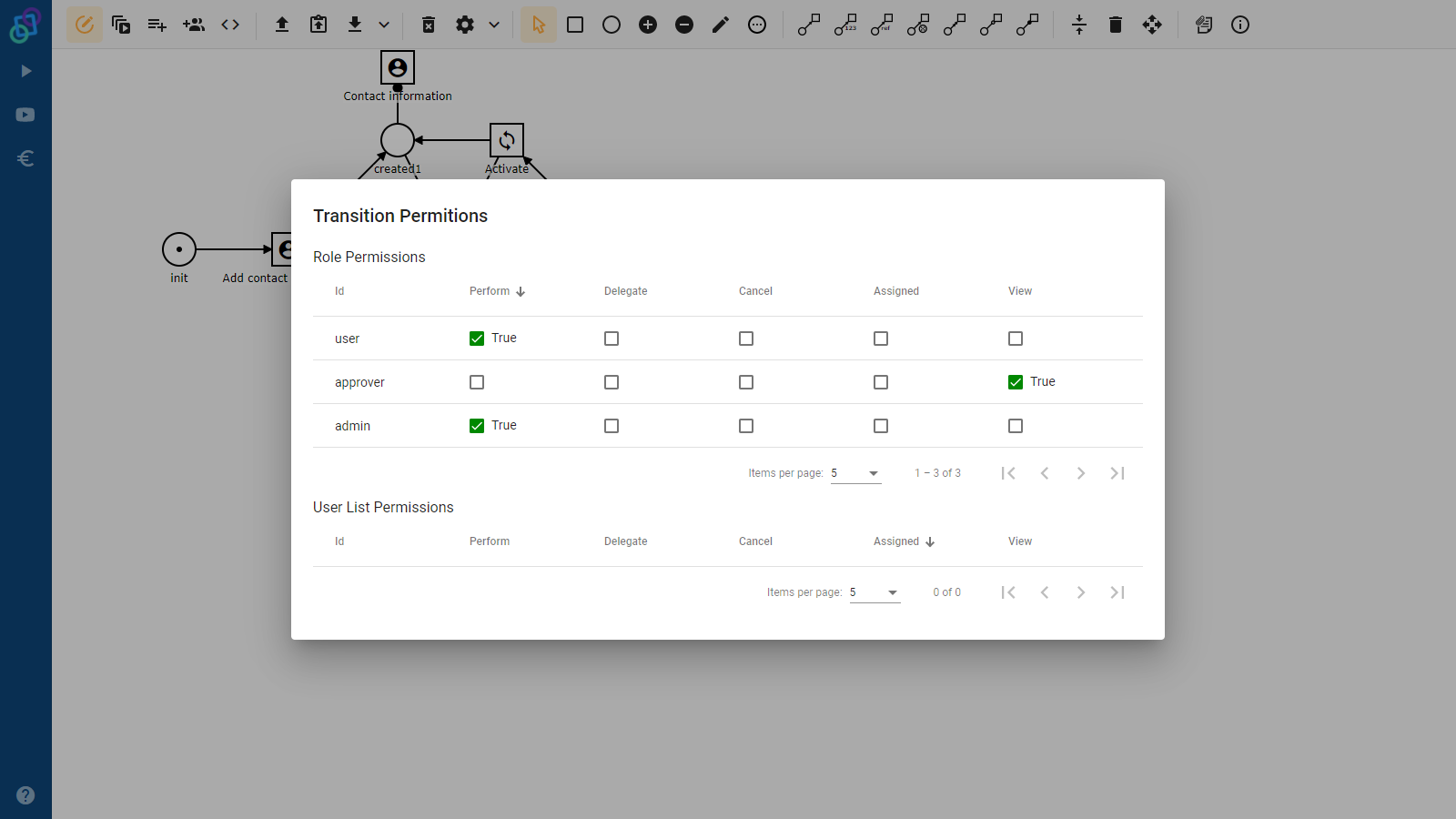
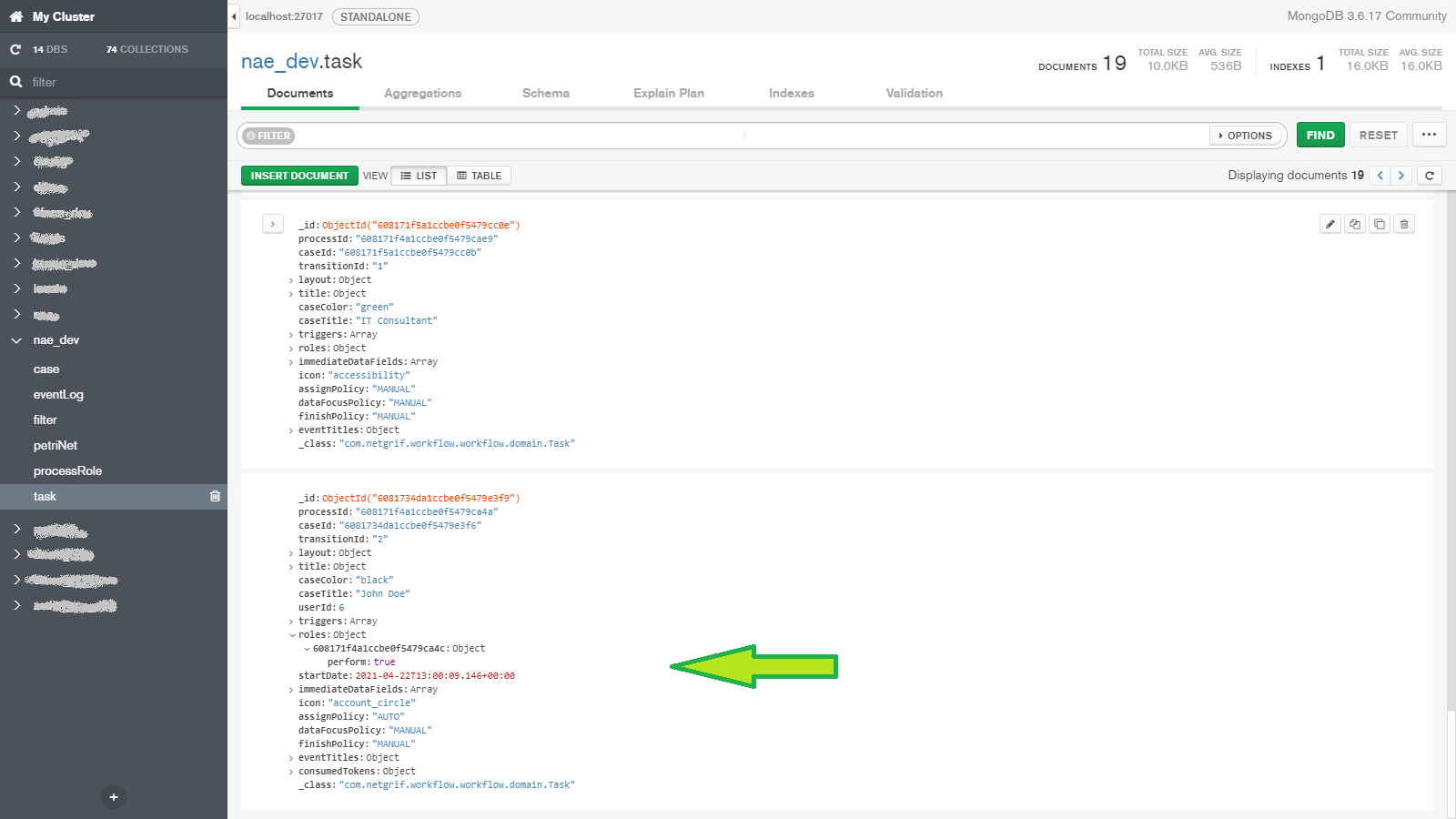
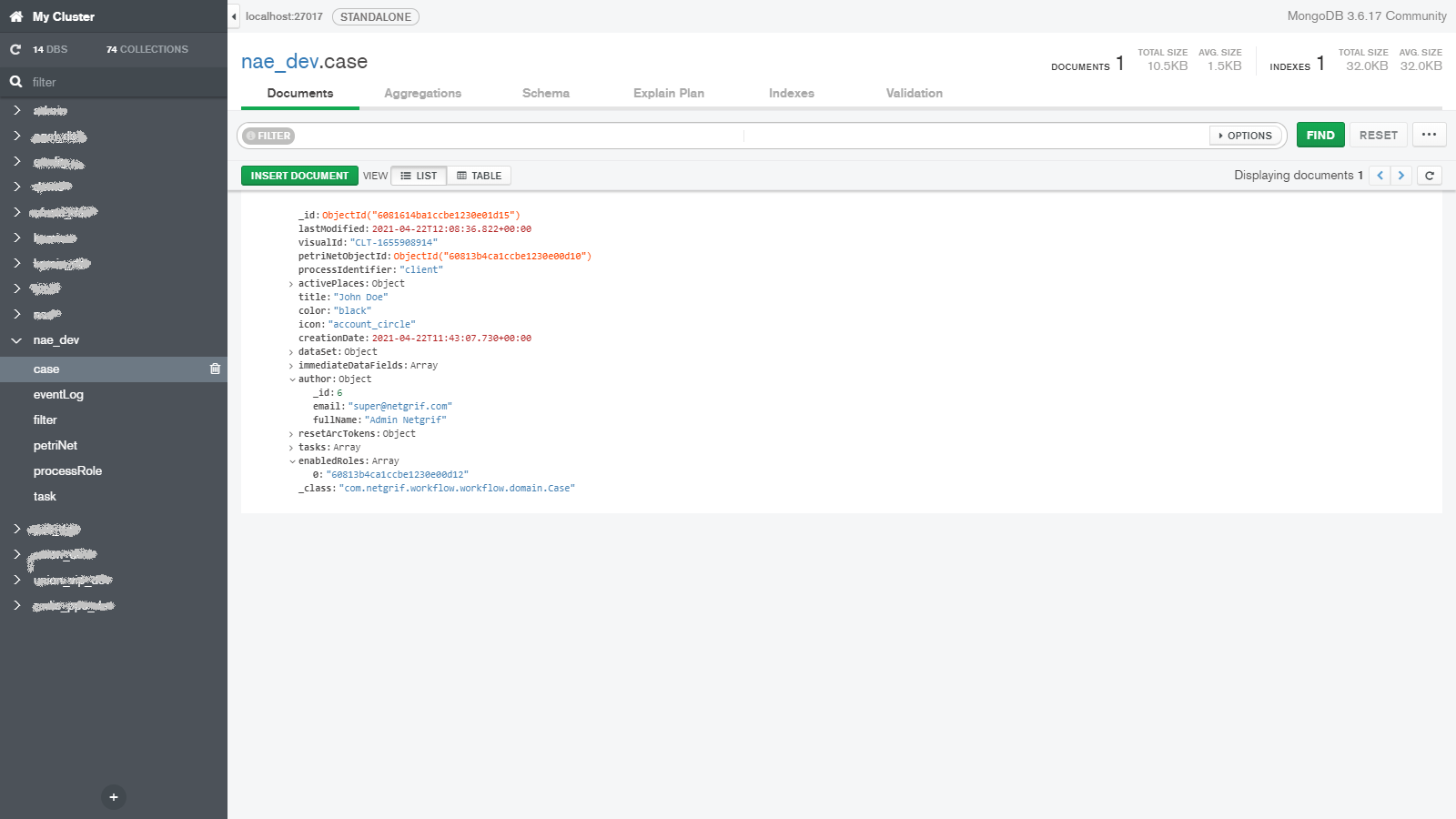
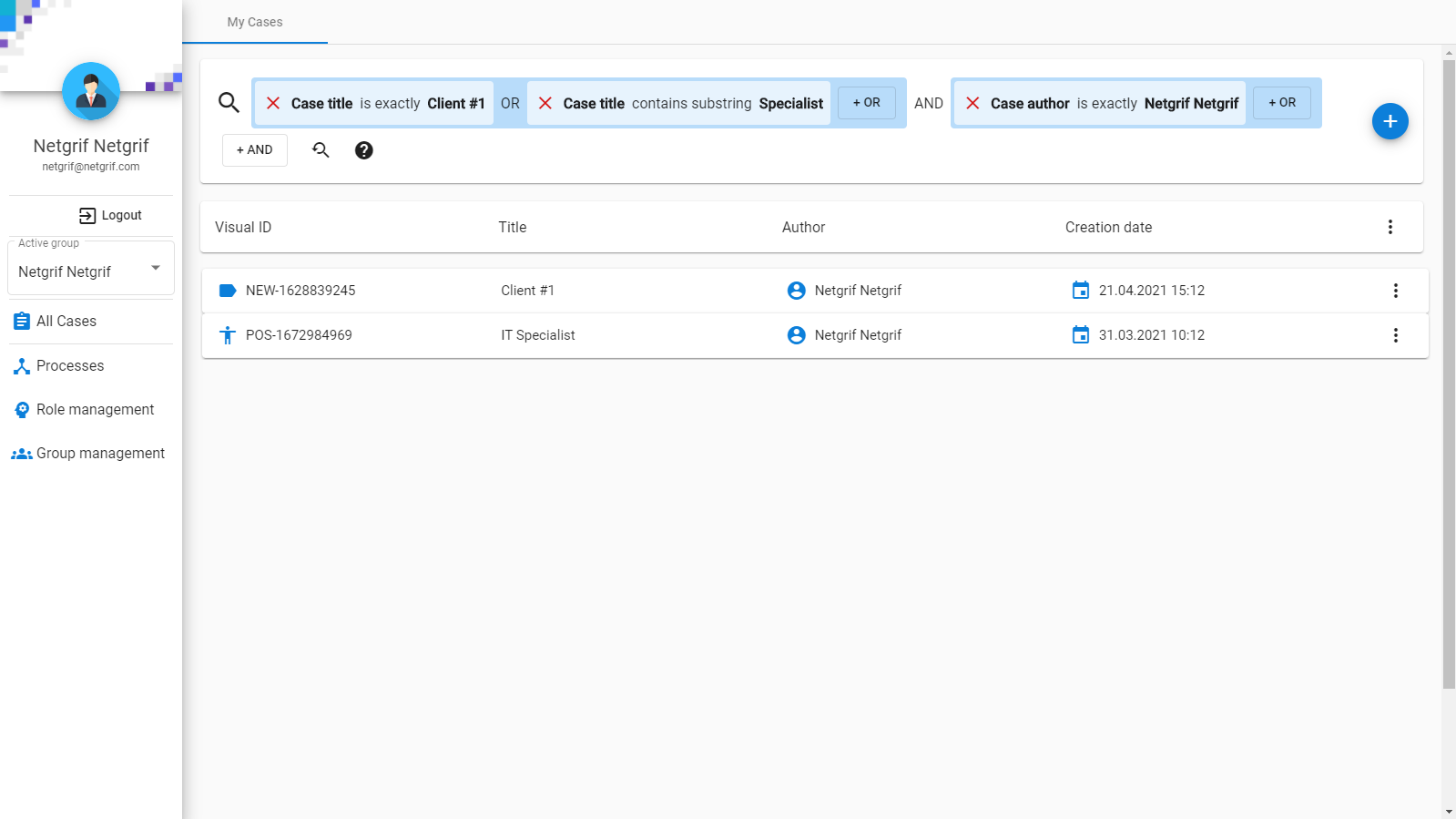
We are going to look at our platform from the point of view of the data and how our design choices influence the data that are created. Then we will look at how this data changes when we interact with the application. Lastly, we will look at how to access this data through the various means available in our platform.
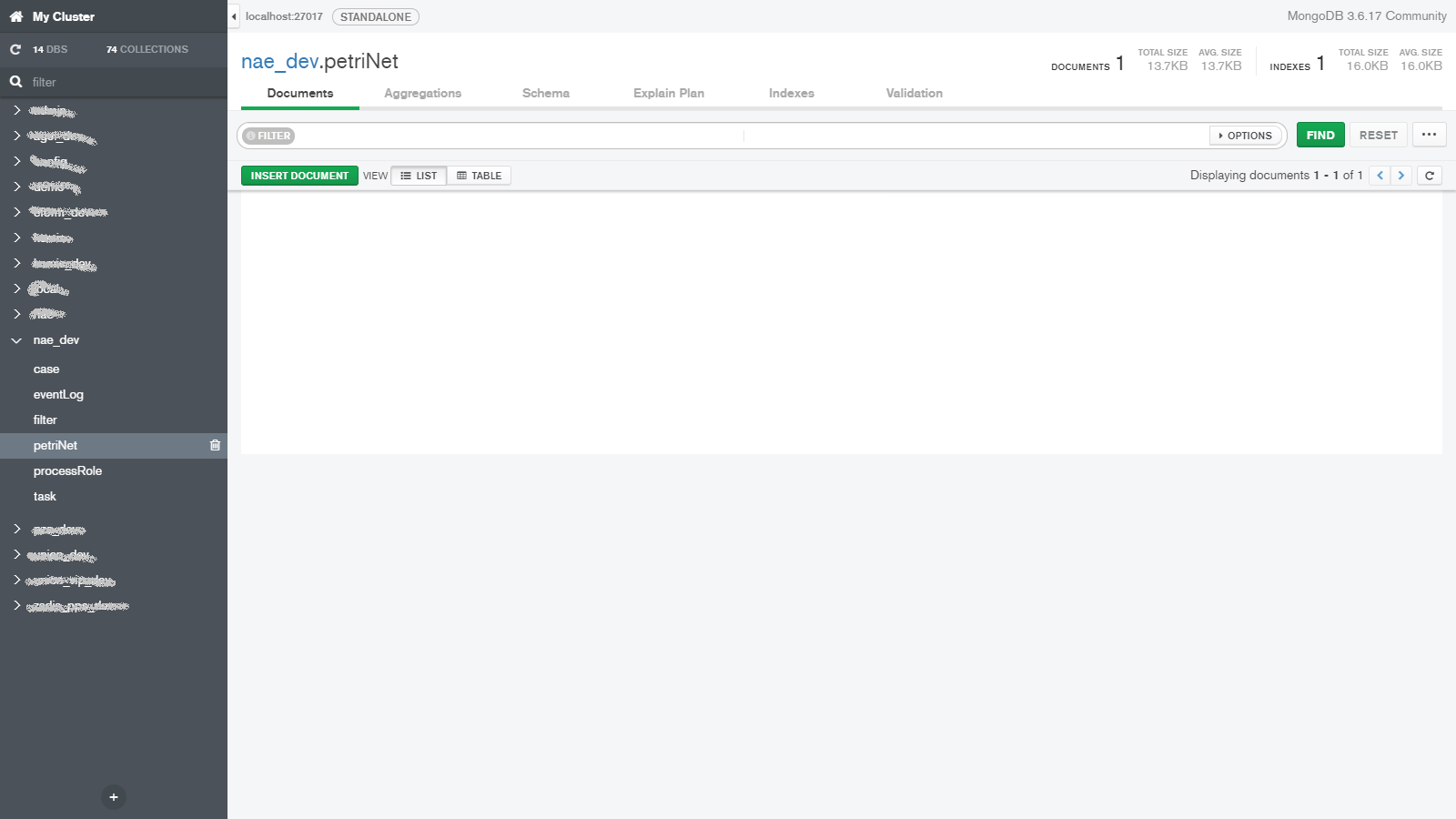
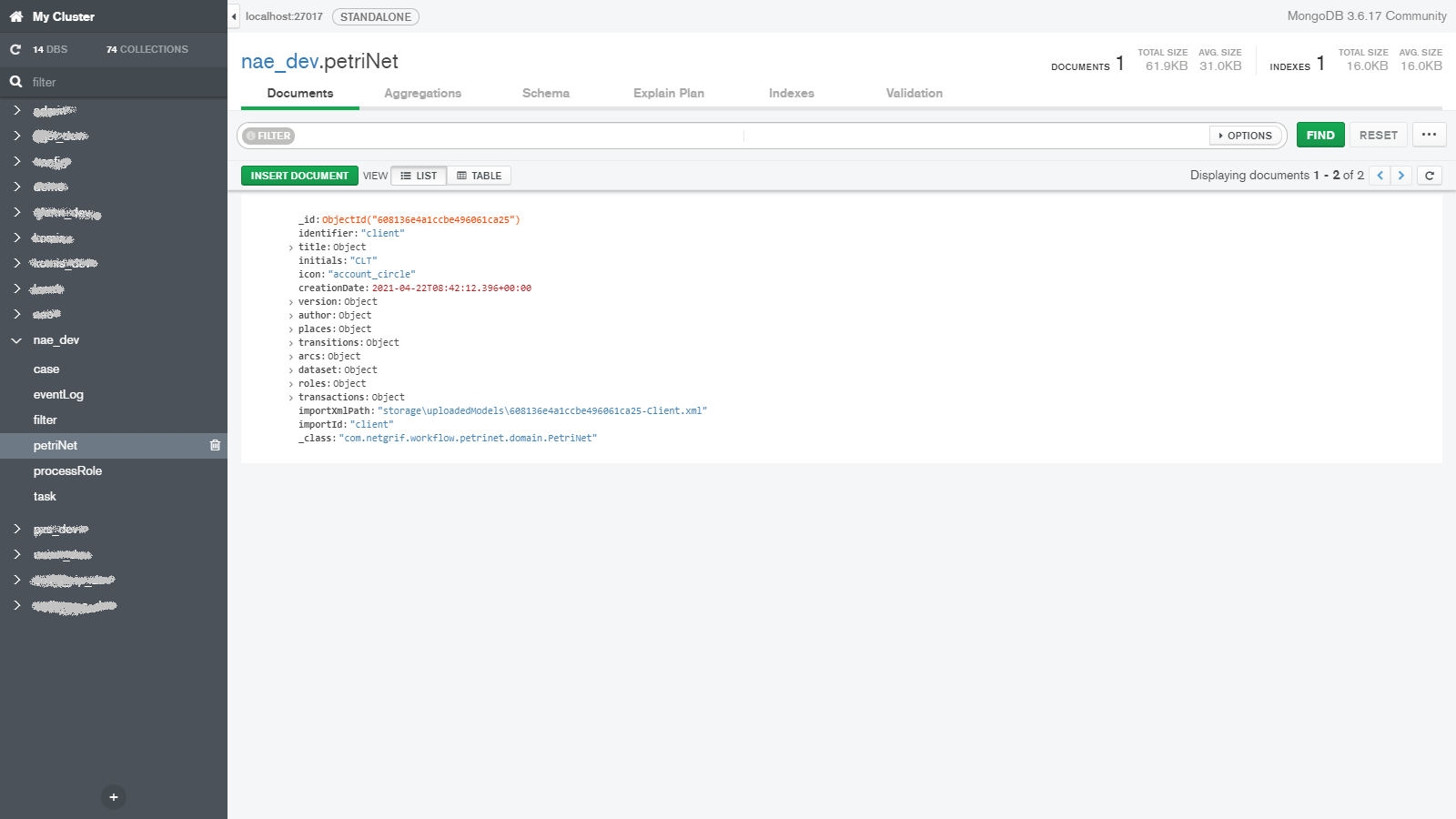
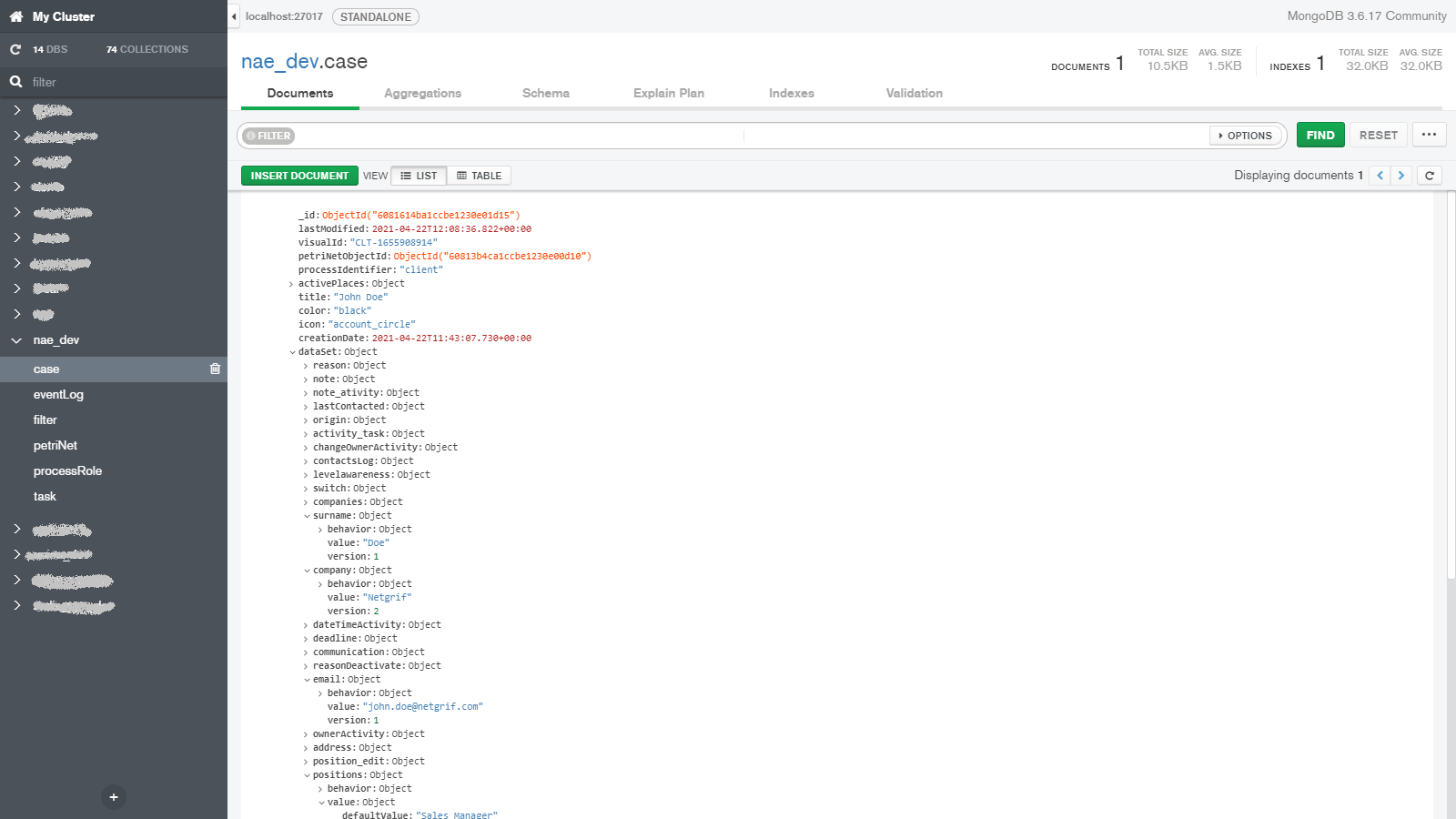
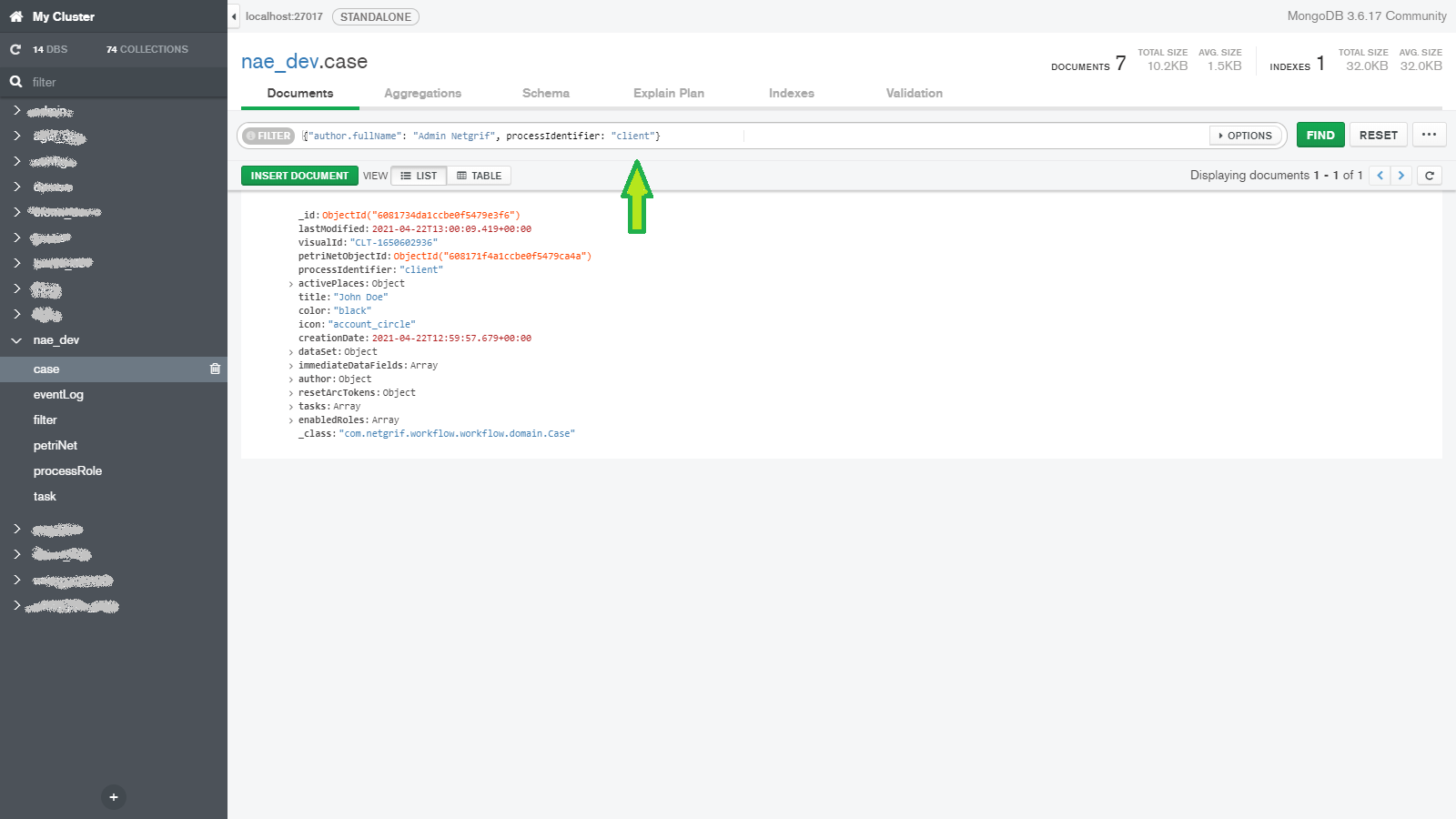
When we talk about data, we have to at least mention how it is stored and since this blog aims to provide some technical insight we have to talk a little bit about the databases. To keep things brief we will only mention the two most important databases used by our platform. To store virtually all the important data we use MongoDB.
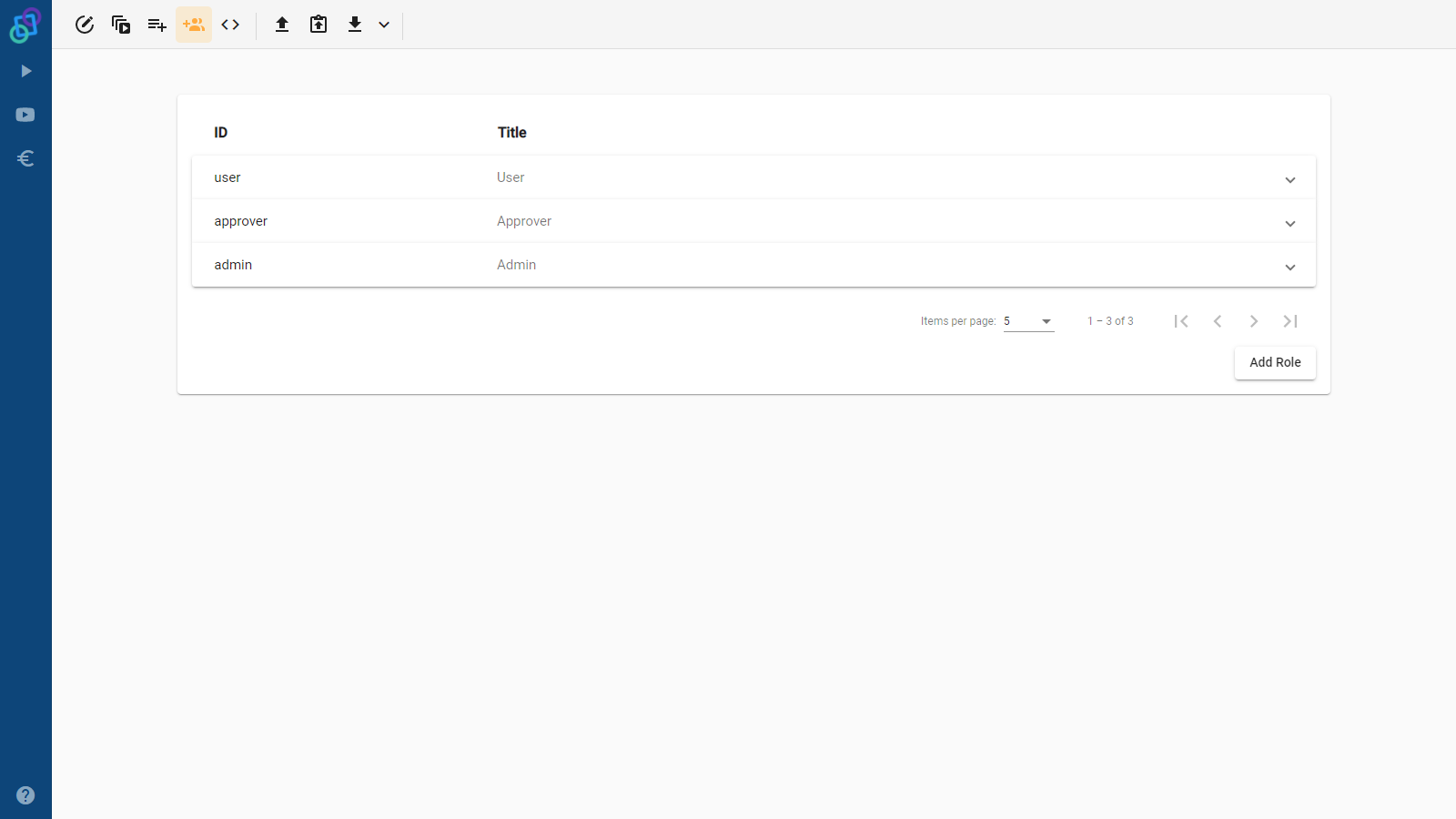
Here we store the three most important things in our platform alongside other data, such as application logs (read more in log blog). The three most important things (in no particular order) are each stored in their own MongoDB collection and they are:
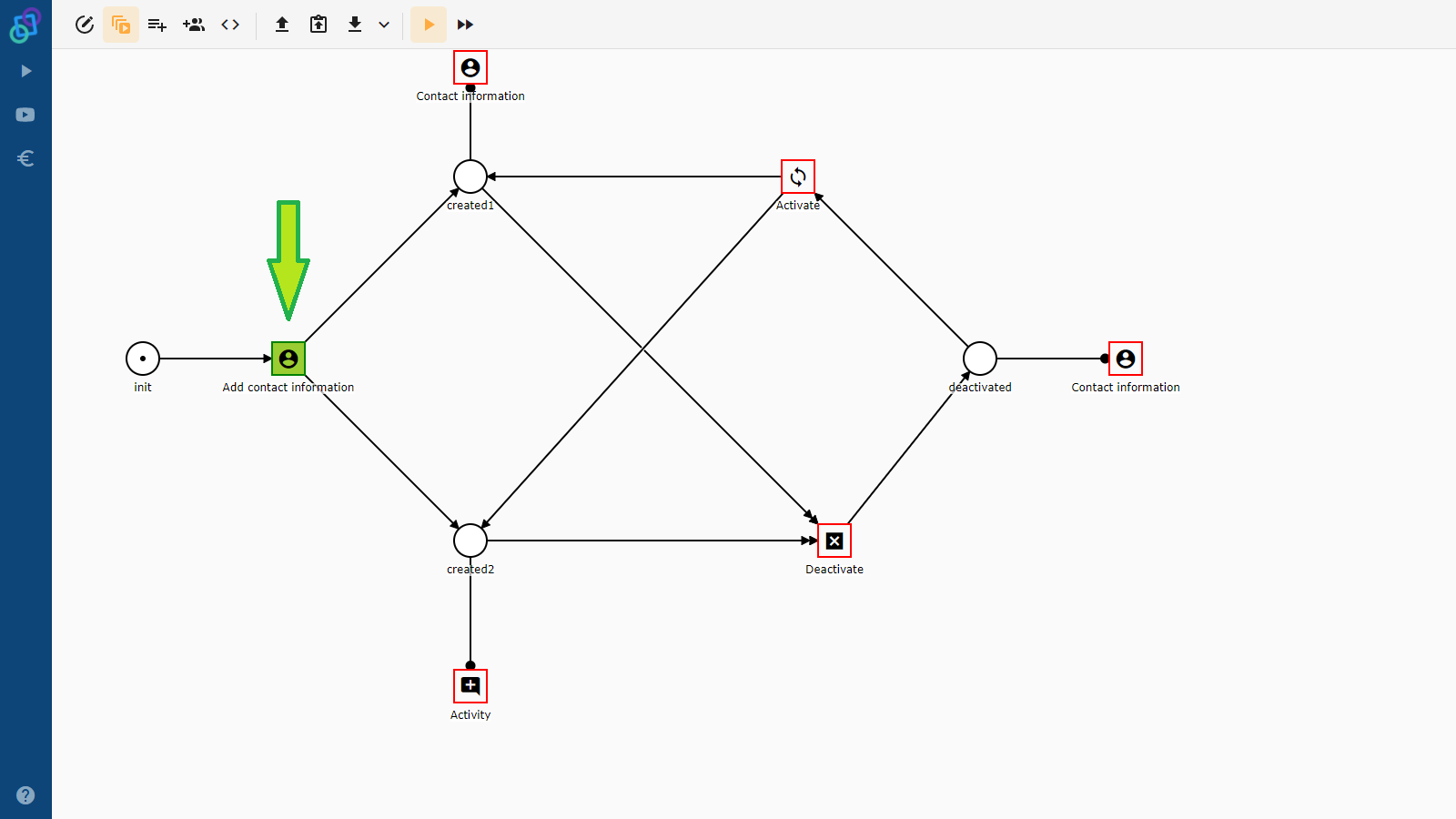
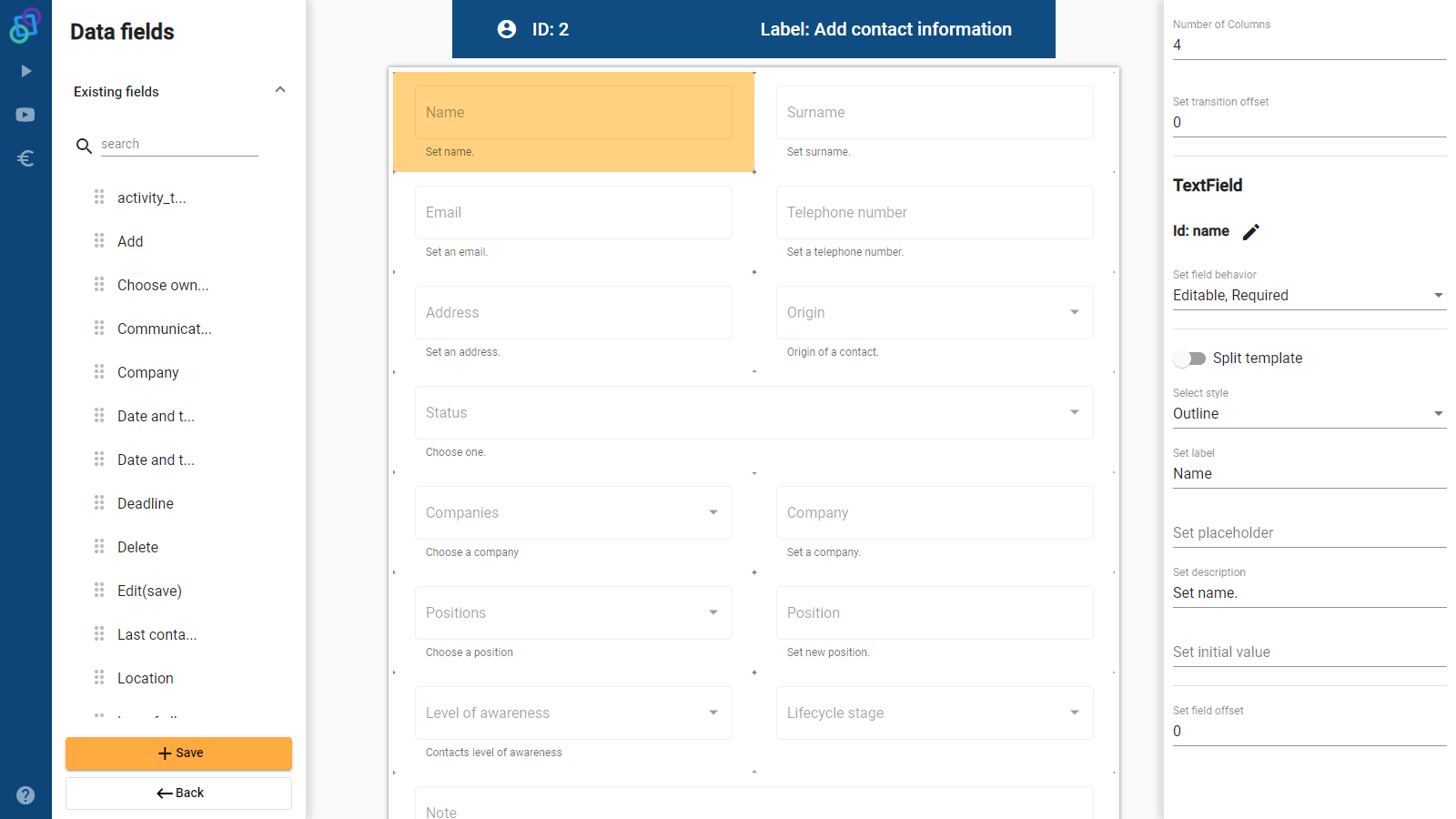
- Processes – the process models themselves
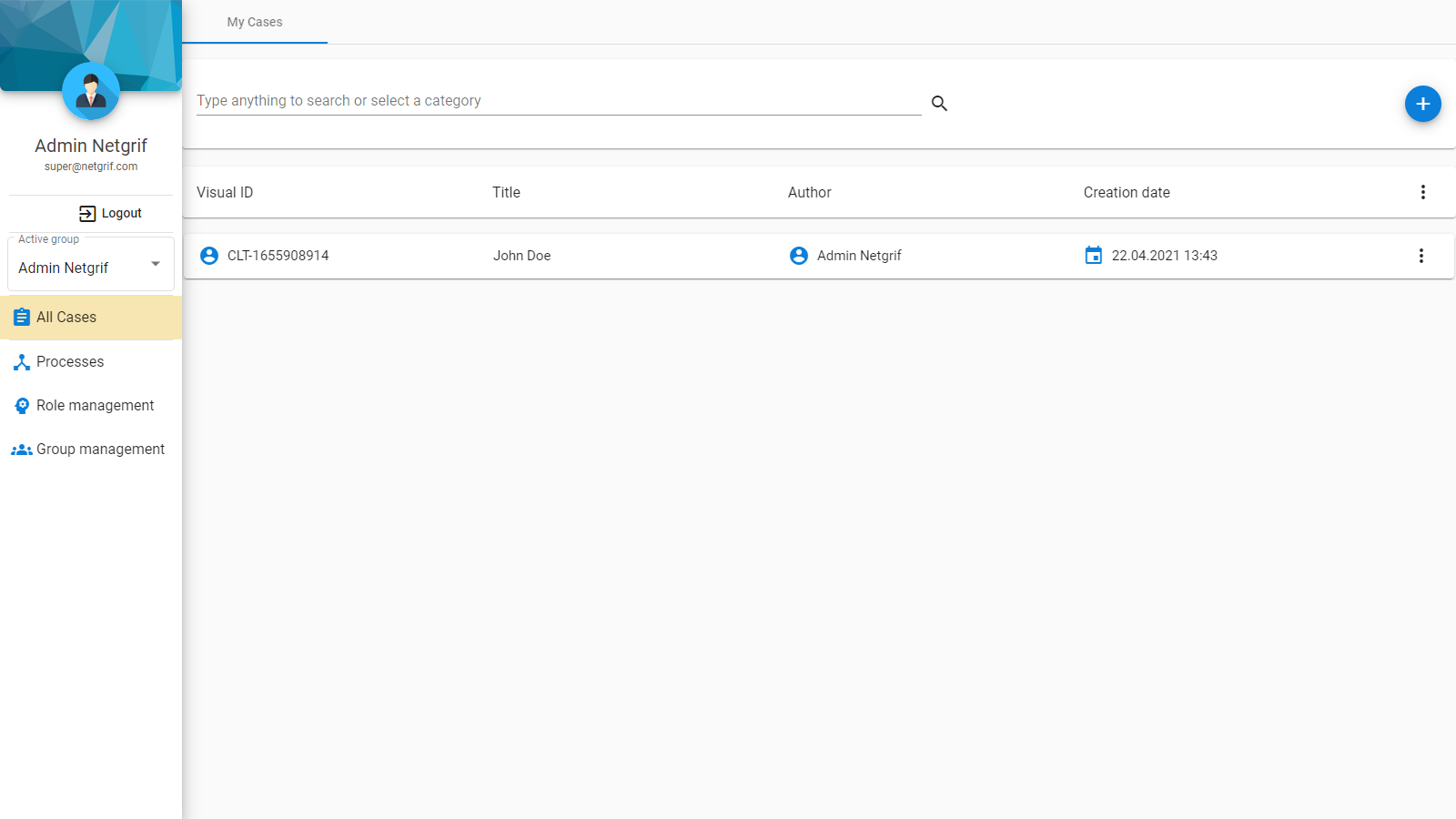
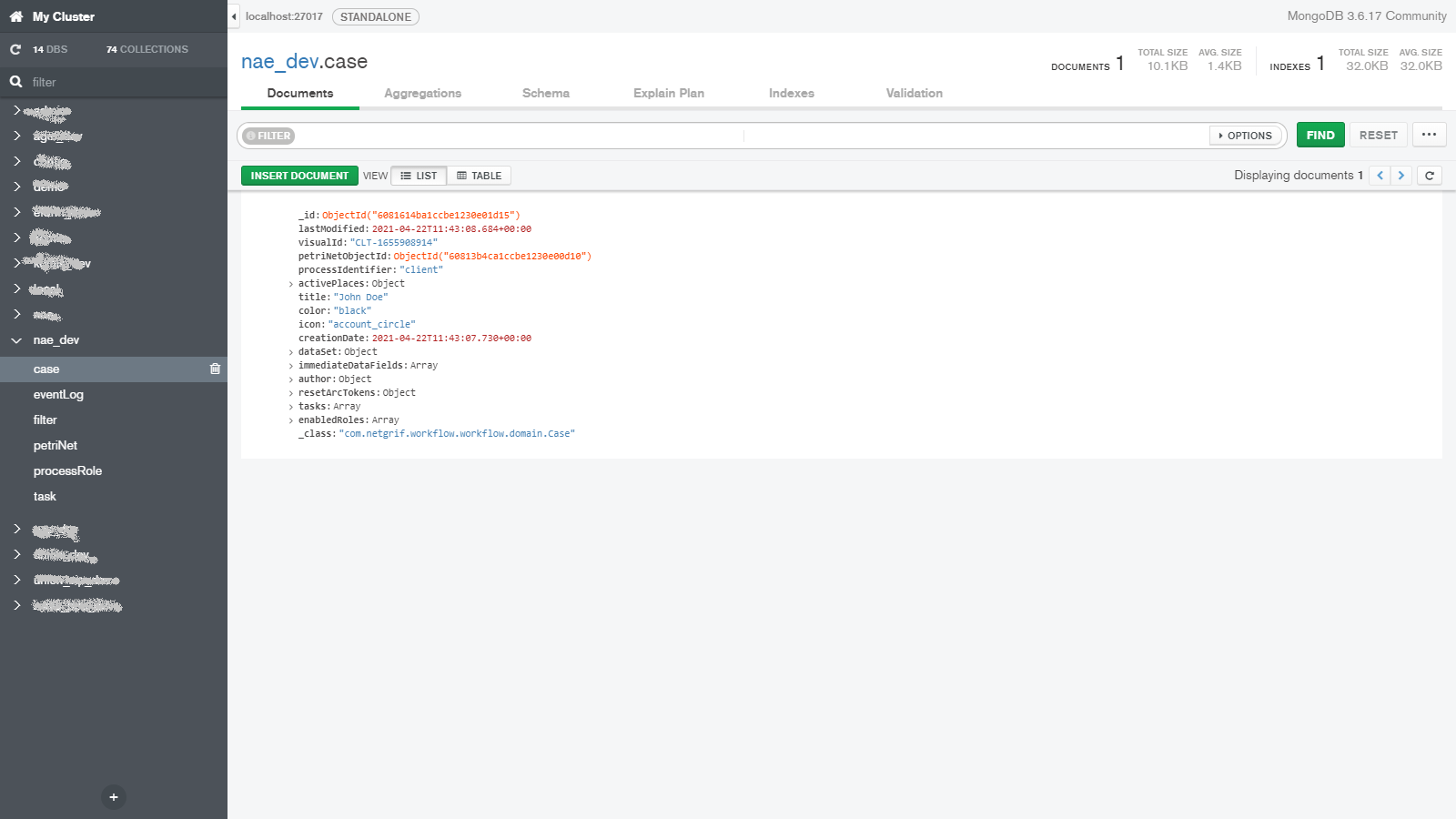
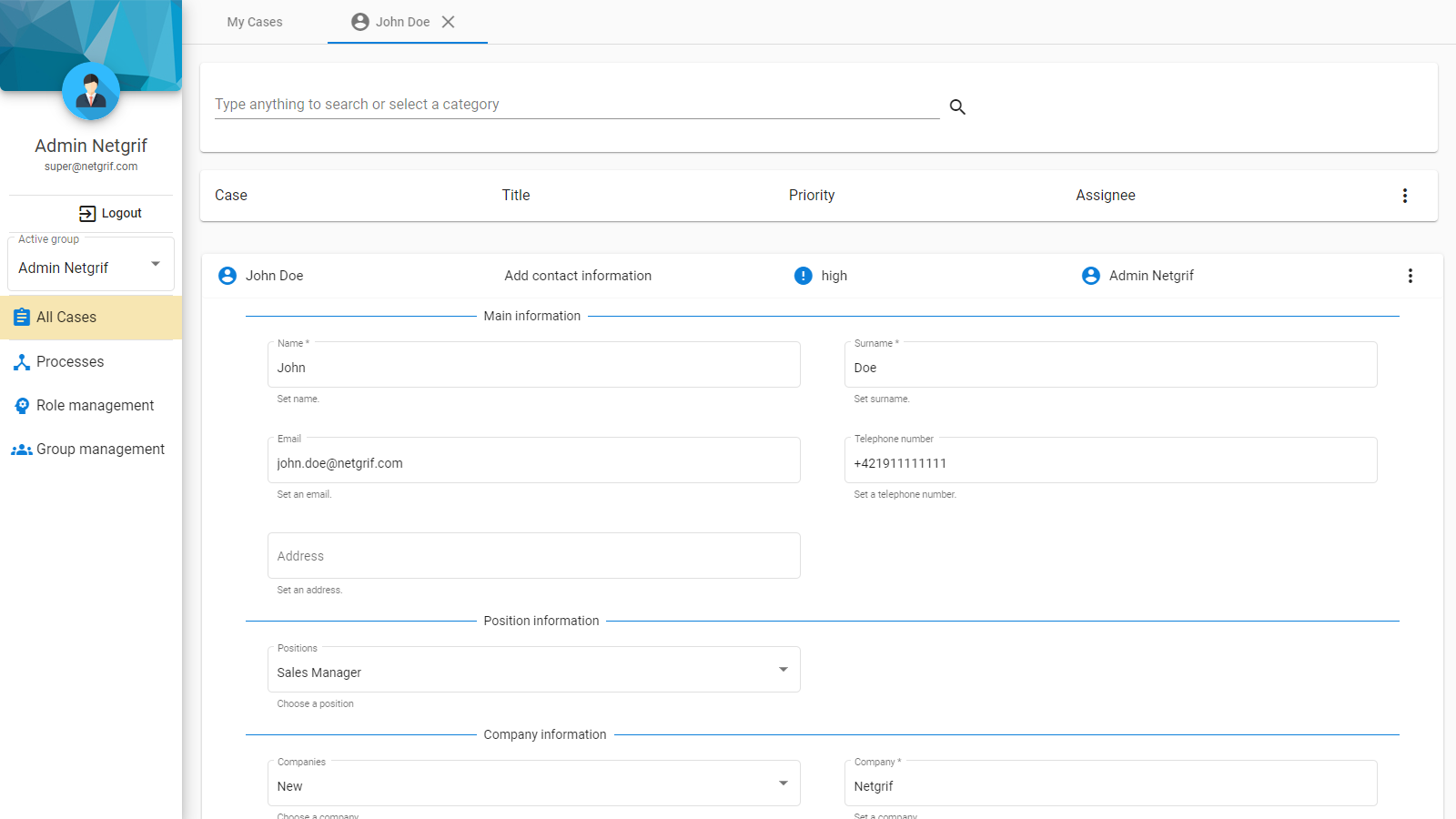
- Cases – the individual instances of the processes
- Tasks – the currently executable operations available in the cases
If none of these ring any bells, we recommend looking at our blog that explains the fundamentals of our platform and then return back to this blog, to get the most out of it. The second database that deserves a mention in this blog is Elasticsearch and we use it to store indexed information about the data in MongoDB, to provide faster, and thus better performance of our platform.