

Document Digitization and Digitalization
INDUSTRY
Other

About
This system is connected with the eTask system which creates tasks for employees to work with digitized documents. Each paper document is in the first step scanned and with help of OCR necessary data are extracted from it. Scanned document together with extracted data sent for processing to the system. Based on the type of document system decides automatically how to categorize the document and what tasks to generate for users.
Batch processing
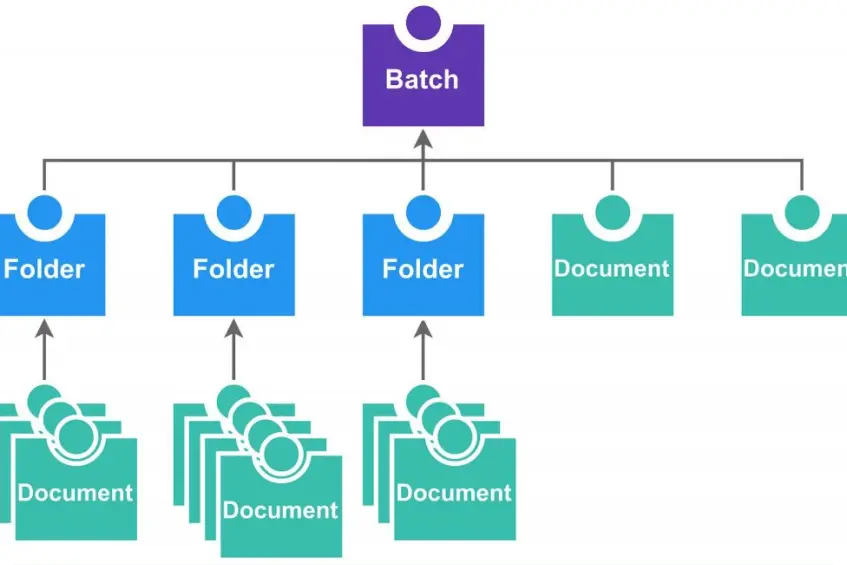
After scanning and data mining by OCR a set of documents – batch – is uploaded on the client’s FTP server to a ‘to-do’ directory. Application is watching this directory and will pick any changes. After the upload, the application automatically creates an instance of the batch process whose role is to unpack the batch of documents into the ‘work’ directory and check its content. The batch can contain any number of single documents or folders. For each document, a new processing instance is created automatically.
The folder processing process first checks the content of the folder if it contains all PDF-XML couples and then for each couple a new document processing process instance is created. This process checks data extracted from the document against a defined set of rules and after a successful check, the document is uploaded together with the corresponding PDF into Document Management System (DMS).
After the document is processed, the instance is notified and waits for the end of processing of the remaining documents in the folder. After the whole folder is processed, the batch process is notified and the batch process is finished after all folders are processed. In case of any error (incorrectly extracted data, incomplete folder, DMS outage etc.) system creates an error task for the administrator.
Document types, metadata and processes
Each physical scanned document is of exactly one type which is uniquely defined in the system by its identifier and validity in time. Document types determine how the individual documents are categorized and what processes shall be started afterwards.
Metadata present in linked XML files are loaded to DMS according to the configuration of the document type. Each document type has its own setting determining which metadata fields are loaded to DMS and what are the default values of fields missing in the XML file or new field values if XML fields should be re-written. Each field is represented in the system by a record defining name, type (text, number, date) and description. Specific document types refer to these records and tie them with records of default values.
Data fields on a document level can be defined as required or optional and can require validation via regular expressions. If these conditions are not met during batch processing, they are subject to manual check by the employee via a check task where the user is requested to correct the data.
A system administrator has full control over document type settings and can add new, update existing or delete old records.
The next processing steps are determined after a document is processed. A document can be designated for storage or further processing. Documents designated for further processing then create new tasks in specific processes according to settings. Based on document type categories data contained in the document, tasks are assigned to specific groups of users.
Processes range from simple with one or few tasks to processes with many tasks where processing takes a long period of time and requires integration with other systems.

Ready to modernize your business operations?
Try our Netgrif Application Builder and get your own Netgrif Platform experience.
Continue reading

Integrated dealer portal – Tatra-Leasing

Advanced Government Agenda System
