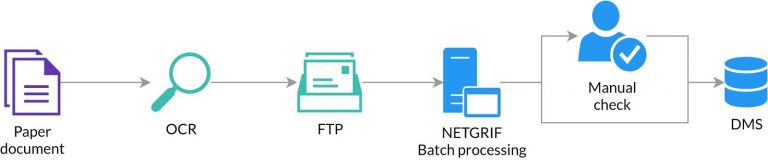
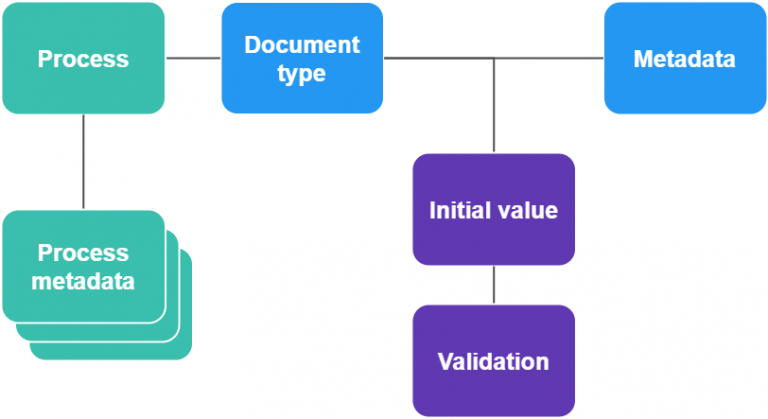
Each physical scanned document is of exactly one type which is uniquely defined in the system by its identifier and validity in time. Document types determine how the individual documents are categorized and what processes shall be started afterwards.
Metadata present in linked XML files are loaded to DMS according to the configuration of the document type. Each document type has its own setting determining which metadata fields are loaded to DMS and what are the default values of fields missing in the XML file or new field values if XML fields should be re-written. Each field is represented in the system by a record defining name, type (text, number, date) and description. Specific document types refer to these records and tie them with records of default values.
Data fields on a document level can be defined as required or optional and can require validation via regular expressions. If these conditions are not met during batch processing, they are subject to manual check by the employee via a check task where the user is requested to correct the data.
A system administrator has full control over document type settings and can add new, update existing or delete old records.
The next processing steps are determined after a document is processed. A document can be designated for storage or further processing. Documents designated for further processing then create new tasks in specific processes according to settings. Based on document type categories data contained in the document, tasks are assigned to specific groups of users.
Processes range from simple with one or few tasks to processes with many tasks where processing takes a long period of time and requires integration with other systems.