


That’s a wrap on DevDays Europe
Last week I had the chance to speak at the DevDays Europe Conference in Vilnius, and it was one of those events where the post-talk conversations ended up being just as valuable as the session itself.

What I talked about
The title of my session was “AI-Native Enterprise Platform — Interpreting Logic, Not Compiling Code.”
The core thesis: most “AI for enterprise apps” tools today are just AI generating JavaScript or full-stack code. That’s millions of tokens per app, inconsistent output across layers, and code nobody can actually verify. At Netgrif, we took a different route – we created Petriflow, a language designed from the ground up for AI to generate enterprise apps reliably. Deterministic enough for the LLM to stay consistent, expressive enough for humans to keep building.
I walked through four perspectives on what makes a platform truly AI-native:
- Object-Centric Processes — one object, all layers
- A language that both humans and AI can generate
- What’s behind that — the runtime that interprets it directly
- Why this is all AI-native — and why the token economics change what AI can actually do

Object-Centric Processes — one object, all layers
This is where most of the post-talk questions ended up. The idea is simple: instead of splitting an enterprise app across process diagrams, data schemas, frontend forms, and backend services, you capture all of it in one object — a Petriflow model. Roles and users, forms, the process model with lifecycle states, data objects (OOP-style attributes — text, number, date, file, user), events and actions, search queries — all in a single artefact.
Why does this matter for AI? Because the whole app fits in a single context window. The LLM sees the full process, data, and UI together — no fragmenting across files, no inconsistency between layers, no “the backend says X but the form says Y” drift.
Then we walked through Netgrif’s development cycle — Input → Generate → Deploy. You start from a BPMN sketch or a natural-language prompt, the Builder (with the AI assistant) produces Petriflow code, and the Platform interprets it directly. No compile step, no code generation in the traditional sense. The spec is the app.
From the deck
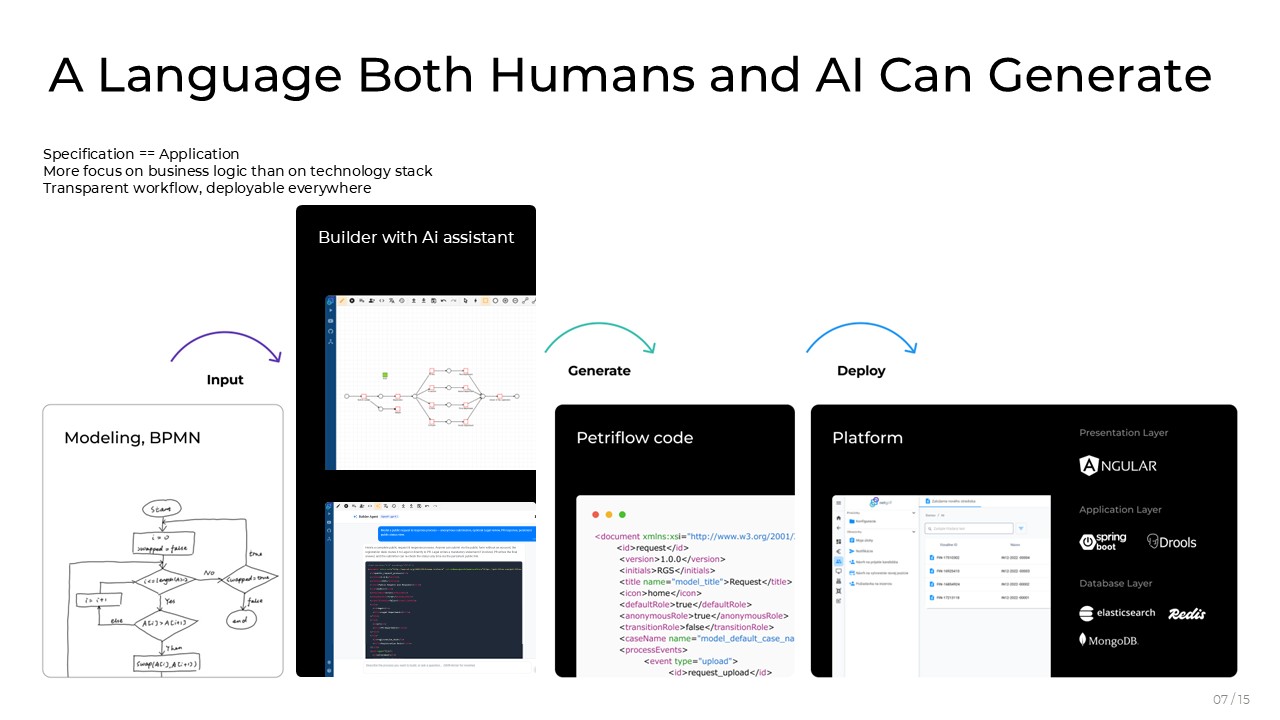
“Specification == Application.”
More focus on business logic than on technology stack. Transparent workflow, deployable everywhere.
The token economics that change everything
This was the part of the talk that got the most head nodding. I shared our estimate of how many tokens an LLM actually needs to generate one complete enterprise application:
- Full-stack custom development: 1–2M tokens (generate HTML, JS, CSS, backend, DB, configs — every layer from scratch)
- Traditional low-code platforms: 250–500k tokens (separate definitions for UI, data, logic — each layer still has its own model)
- Netgrif (Petriflow, all-in-one): 20–50k tokens (one model = process, data, UI, and roles in a single artefact)
That’s roughly 10× fewer tokens than traditional low-code and 40× fewer than custom full-stack code. But the cost angle isn’t the point — the point is that fewer tokens change what AI can actually do:
- Higher reliability — the whole app fits in one context window, so there’s no fragmenting and no inconsistency between layers
- Faster iteration — generation in seconds, not minutes. Real-time conversational editing of full apps becomes feasible
- Lower cost — cents instead of dollars per app. AI-native generation becomes viable at enterprise scale, not just for demos
I also did a quick live demo at builder.netgrif.cloud — built a generic request app with 3 tasks, 4 user roles, and 2 UI forms in about 5 minutes — and showed our conversational AI builder at ai-preview.builder.dev.netgrif.cloud, where you describe the process in plain English and get executable Petriflow back.
What’s next
If the topic resonated with you, or if you missed the session and are curious, I’m happy to:
- Share the slides
- Walk through specific parts of the demo one-on-one
- Talk about how we approach AI-nativeness at Netgrif
Drop me a message on LinkedIn or a comment, and I’ll get back to you. You can also explore Petriflow on github.com/netgrif — the language itself is open-source, so if you’re curious how an AI-native modelling language is built, the source is right there.
Thanks again to everyone who came, asked questions, and stayed for the hallway conversations. See you at the next one.

Want to try AI-native Petriflow generation yourself?
Open the Builder, describe a process, and watch the AI generate the full app — exactly the demo I showed at DevDays.