
Events & Actions of Application Platform
In our previous blogs we have mentioned actions and events. Today we will take a closer look at them.
You may already know that actions in Petriflow are small blocks of code executed during the lifecycle of the modelled process. Why are actions useful? You can indeed create fairly complex applications by using the modelling techniques of our platform alone. In order to create truly rich applications, you need to enrich the modelled processes with custom logic that is relevant to the process you are modelling. We believe that the expression of these domain-specific requirements should be done in a straightforward, low-code manner and in the Petriflow language it takes the form of actions.
Ok, you have enriched your process with some actions, but when are they executed? This is where events come into play. The modelled processes and their components – their tasks – have a certain lifecycle. Developers of process-driven applications can hook into this lifecycle when certain events happen and can react to these events by executing actions. Each event in the lifecycle is split into 3 parts, the pre-event, the event and the post-event. We can choose whether our actions are executed before (pre-) or after (post-) the event.

The choice of the correct phase matters because of two factors. First, the state of the underlying Petri net. Most events change the state of the Petri net or the associated data in some way. The actions are executed in the current state and so if the event changes the state we effectively have a choice, whether we want to execute the event in the old or the new state.
For example, we might want to give the users of our process-driven application the ability to undo a change to one of the forms. In this situation, we need to execute our event before the value is changed so that we can save the previous value and use it for the undo operation later on.
An example of a situation where we want to execute a post-action is when we want to assign the following task to some specific person. If this following task depends on tokens produced by our current task, we need our task to produce the tokens first, so that the following task can consume them. Tokens are produced during the finish event. Therefore, we need to wait for our action and execute it in the new state (in the new marking of the Petri net) to successfully assign the following task to our desired user.
The second factor where the choice of pre-actions or post-actions is important is error handling. Error handling is an important part of process design because we don’t want our process to end up in unforeseen and unexpected states. Imagine a situation where we integrate our application with a third party such as a bank to perform some online payment. The payment can either succeed or fail and we want to make sure that the process continues only if the payment was successful. If not we want to remain in the same state and try again later. By performing the payment in a pre-action we can interrupt the chain prematurely and the associated event (such as finishing a task) will not execute. Thanks to this behaviour we can prevent our process-driven application to change state if the payment is not successful.
Similarly, if we want the application to behave in such a way that a failure won’t prevent the execution of the associated event, we can put the code into a post-action and this will not cancel the execution of the event.
The following diagram shows a big-picture overview of how the events are triggered by the users, how these events affect the state of the application and how this change is propagated back to the user.
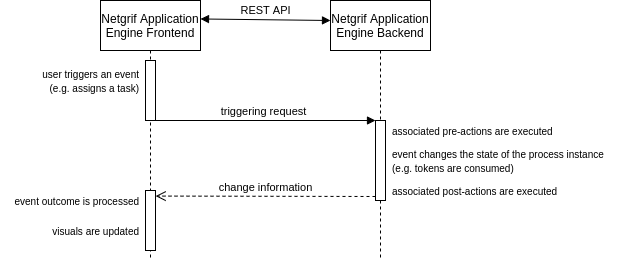
The Petriflow language categorises events into three groups – process related, case (instance) related and case attribute related (tasks and data). Regardless of their categorisation, all of them can be reacted to with your actions in the same way.
Actions have access to the application engine API and can interact with the processes, cases and tasks contained within. These interactions often correspond to some event, such as setting new values, creating new cases, or assigning a task. These events can have more actions associated with them, so a chain reaction of events and actions can occur. This allows you to create very rich applications from simple building blocks.
We hope this deeper dive into the world of actions and events was insightful. Follow our blog to get more in-depth articles covering the Netgrif platform.
